HashMap/HashSet/HashTable
HashMap
存储<K,V>的容器,并且保证其中的K是唯一的(可以为null),线程不安全
定义
继承AbstractMap,实现Map
1
| public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
|
底层存储
Java8中,HashMap底层实际上是基于一个Node类型的数组
1
| transient Node<K,V>[] table;
|
属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
| static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; static final int MAXIMUM_CAPACITY = 1 << 30; static final float DEFAULT_LOAD_FACTOR = 0.75f; static final int TREEIFY_THRESHOLD = 8; static final int UNTREEIFY_THRESHOLD = 6; static final int MIN_TREEIFY_CAPACITY = 64;
|
构造函数
1 2 3 4 5 6 7 8 9 10 11 12
| public HashMap() public HashMap(int initialCapacity, float loadFactor) public HashMap(int initialCapacity) public HashMap(Map<? extends K, ? extends V> m)
|
底层存储结构
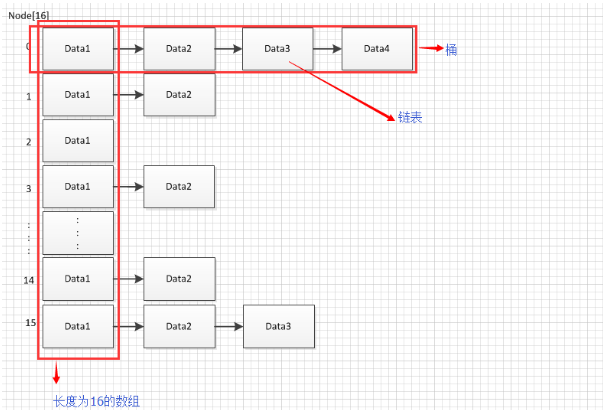
resize与树化的缘由:随着结点的增多,单个桶中的元素越来越大,即链表的长度越来越长,导致链表的相关操作的性能越来越差
resize
具体resize方法可查看具体源码
1
| final Node<K, V>[] resize()
|
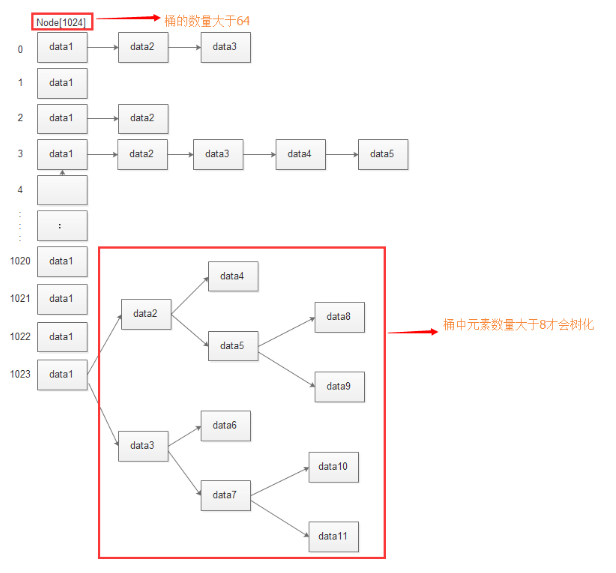
容量不能超过MAXIMUM_CAPACITY上限,新容量为旧容量的2倍,新阀值为旧阀值的2倍
树化
当HashMap的容量大于MIN_TREEIFY_CAPACITY 并且桶中元素数量大于等于TREEIFY_THRESHOLD 时,
该桶中的元素结构就会由链表结构转成树结构以提高性能
具体可查看树化函数源码
1 2 3 4
| final void treeifyBin(Node<K,V>[] tab, int hash) final void treeify(Node<K,V>[] tab)
|
把链表中每个结点都替换成树结点,实际上是创建一个新链表,结点类型由Node变为TreeNode
put(key,value)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59
| public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
|
get(Object key)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
|
HashSet
元素唯一且无序
定义
继承AbstractSet,实现Set
1
| public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
|
属性
1 2 3
| private transient HashMap<E,Object> map; private static final Object PRESENT = new Object();
|
构造函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
| public HashSet() { map = new HashMap<>(); } public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); } public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); } public HashSet(int initialCapacity) { map = new HashMap<>(initialCapacity); } * 底层使用LinkedHashMap,其他几个都是HashMap * dummy参数,仅仅是为了区别于上面第3个构造方法 * 访问权限是包权限,不对外公开,实际上这个构造方法在LinkedHashSet被使用到 */ HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); }
|
常用方法
基本都是基于HashMap的操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| *往集合中新增元素,map.put(e, PRESENT)会返回map中插入前旧的value,即如果key已经存在, *那么返回PRESENT否则返回NULL。从这里可以看出,如果新增的key已存在add方法会返回false。 */ public boolean add(E e) { return map.put(e, PRESENT) == null; } public boolean remove(Object o) { return map.remove(o) == PRESENT; } public Iterator<E> iterator() { return map.keySet().iterator(); }
|
HashTable
与HashMap相比,HashTable中的key和value都不允许为null
线程安全,类中大部分方法都为synchronized修饰的方法
定义
继承Dictionary,实现Map
1
| public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable
|
具体内部实现,参阅源码。。
